12/02/2022
Note: The \037 sequence appearing in the code snippets is one
character, escaped for readability.
It’s been eight years since I started using Emacs and Emacs Lisp and I
still keep running into dusty corners. Traditionally, Lisp dialects
use the semicolon for line comments, with block and s-expression
comments being optional features.
| Dialect |
Line comment |
Block comment |
S-expression comment |
|---|
| Clojure, Hy |
; |
n/a |
#_ |
| Common Lisp |
; |
#|...|# |
#+(or) |
| Emacs Lisp, Lush |
; |
n/a |
n/a |
| ISLisp, LFE, uLisp |
; |
#|...|# |
n/a |
| NewLisp |
;, # |
n/a |
n/a |
| Picolisp |
# |
#{...}# |
n/a |
| Racket, Scheme |
; |
#|...|# |
#; |
| TXR Lisp |
; |
n/a |
#; |
| WAT |
;; |
(;...;) |
n/a |
Emacs Lisp is special though. Here’s an unusual section from the
Emacs Lisp reference on comments:
The #@COUNT construct, which skips the next COUNT characters,
is useful for program-generated comments containing binary data.
The Emacs Lisp byte compiler uses this in its output files (see
“Byte Compilation”). It isn’t meant for source files, however.
At first sight, this seems useless. This feature is meant to be used
in .elc, not .el files and looking at a file produced by the
byte compiler, its only use is to emit docstrings:
;;; This file uses dynamic docstrings, first added in Emacs 19.29.
[...]
#@11 docstring\037
(defalias 'my-test #[...])
This is kind of like a block-comment, except there is no comment
terminator. For this reason, the characters to be commented out need
to be counted. You’d think that the following would work, but it
fails with an “End of file during parsing” error:
(defvar my-variable #@8 (/ 1 0) 123)
It took me a dive into the reader to find out why:
#define FROM_FILE_P(readcharfun) \
(EQ (readcharfun, Qget_file_char) \
|| EQ (readcharfun, Qget_emacs_mule_file_char))
static void
skip_dyn_bytes (Lisp_Object readcharfun, ptrdiff_t n)
{
if (FROM_FILE_P (readcharfun))
{
block_input (); /* FIXME: Not sure if it's needed. */
fseek (infile->stream, n - infile->lookahead, SEEK_CUR);
unblock_input ();
infile->lookahead = 0;
}
else
{ /* We're not reading directly from a file. In that case, it's difficult
to reliably count bytes, since these are usually meant for the file's
encoding, whereas we're now typically in the internal encoding.
But luckily, skip_dyn_bytes is used to skip over a single
dynamic-docstring (or dynamic byte-code) which is always quoted such
that \037 is the final char. */
int c;
do {
c = READCHAR;
} while (c >= 0 && c != '\037');
}
}
Due to encoding difficulties, the #@COUNT construct is always used
with a terminating \037 AKA unit separator character. While it
seems that the FROM_FILE_P macro applies when using the reader
with get-file-char or get-emacs-mule-file-char (which are used
by load internally), I never managed to trigger that code path.
The reader therefore seems to always ignore the count argument,
essentially turning #@COUNT into a block comment facility.
Given this information, one could obfuscate Emacs Lisp code to hide
something unusual going on:
(message "Fire the %s!!!" #@11 "rockets")\037
(reverse "sekun"))
A more legitimate usecase is a multi-line shebang:
#!/bin/sh
#@0 -*- emacs-lisp -*-
exec emacs -Q --script "$0" -- "$@"
exit
#\037
(when (equal (car argv) "--")
(pop argv))
(while argv
(message "Argument: %S" (pop argv)))
In case you want to experiment with this and want to use the correct
counts, here’s a quick and dirty command:
(defun cursed-elisp-block-comment (beg end)
(interactive "r")
(save-excursion
(save-restriction
(narrow-to-region beg end)
(goto-char (point-min))
;; account for space and terminator
(insert (format "#@%d " (+ (- end beg) 2)))
(goto-char (point-max))
(insert "\037"))))
There’s one more undocumented feature though, #@00 is
special-cased as EOF comment:
/* Read a decimal integer. */
while ((c = READCHAR) >= 0
&& c >= '0' && c <= '9')
{
if ((STRING_BYTES_BOUND - extra) / 10 <= nskip)
string_overflow ();
digits++;
nskip *= 10;
nskip += c - '0';
if (digits == 2 && nskip == 0)
{ /* We've just seen #@00, which means "skip to end". */
skip_dyn_eof (readcharfun);
return Qnil;
}
}
The EOF comment version can be used to create polyglots. An Emacs Lisp
script could end with #@00, then concatenated with a file
tolerating leading garbage. The ZIP format is known for its permissive
behavior, thereby allowing you to embed several resources into one
file:
[wasa@box ~]$ cat polyglot.el
(message "This could be a whole wordle game")
(message "I've attached some dictionaries for you though")#@00
[wasa@box ~]$ cat polyglot.el wordle.zip > wordle.el
[wasa@box ~]$ file wordle.el
wordle.el: data
[wasa@box ~]$ emacs --script wordle.el
This could be a whole wordle game
I've attached some dictionaries for you though
[wasa@box ~]$ unzip wordle.el
Archive: wordle.el
warning [wordle.el]: 109 extra bytes at beginning or within zipfile
(attempting to process anyway)
inflating: wordle.de
inflating: wordle.uk
This could be combined with the multi-line shebang trick to create a
self-extracting archive format. Or maybe an installer? Or just a
script that can access its own resources? Let me know if you have any
interesting ideas.
19/12/2021
I’ve discovered a trivial stored XSS vulnerability in Checkmk 1.6.0p18
during an on-site penetration test and disclosed it responsibly to the
tribe29 GmbH. The vendor promptly confirmed the issue, fixed it and
announced an advisory. I’ve applied for a CVE, but didn’t get around
explaining the vulnerability in detail, therefore I’m publishing this
blog post to complete the process.
Impact
The vulnerability requires an authenticated attacker with permission
to configure and share a custom view. Given these prerequisites, they
can inject arbitrary JavaScript into the view title by inserting a
HTML link with a JavaScript URL. If the attacker manages to trick a
user into clicking that link, the JavaScript URL is executed within
the user’s browser context.
There is a CSP policy in place, but it does not mitigate inline
JavaScript code in event handlers, links or script tags. An attacker
could therefore obtain confidential user data or perform UI
redressing.
The vulnerable code has been identified in versions below 1.6.0p18,
such as 1.6.0 and older. It is unclear in which version the
vulnerability has been introduced, therefore it’s recommended to
update to 1.6.0p19/2.0.0i1 or newer.
Detailed description
The Checkmk GUI code uses a WordPress-style approach to handle HTML:
User input is encoded using HTML entities, then selectively decoded
with a regular expression looking for simple tags. As a special case,
the <a> tag gets its href attribute unescaped as well to
enable hyperlinks. The attribute is not checked for its protocol,
thereby allowing URLs such as javascript:alert(1).
class Escaper(object):
def __init__(self):
super(Escaper, self).__init__()
self._unescaper_text = re.compile(
r'<(/?)(h1|h2|b|tt|i|u|br(?: /)?|nobr(?: /)?|pre|a|sup|p|li|ul|ol)>')
self._quote = re.compile(r"(?:"|')")
self._a_href = re.compile(r'<a href=((?:"|').*?(?:"|'))>')
[...]
def escape_text(self, text):
if isinstance(text, HTML):
return "%s" % text # This is HTML code which must not be escaped
text = self.escape_attribute(text)
text = self._unescaper_text.sub(r'<\1\2>', text)
for a_href in self._a_href.finditer(text):
text = text.replace(a_href.group(0),
"<a href=%s>" % self._quote.sub("\"", a_href.group(1)))
return text.replace("&nbsp;", " ")
The above code is used for HTML generation. To exploit it, I started
looking for a HTML form and found that when editing a custom view, no
user input validation is performed on the view title (as opposed to
the view name).
def page_edit_visual(what,
all_visuals,
custom_field_handler=None,
create_handler=None,
load_handler=None,
info_handler=None,
sub_pages=None):
[...]
html.header(title)
html.begin_context_buttons()
back_url = html.get_url_input("back", "edit_%s.py" % what)
html.context_button(_("Back"), back_url, "back")
[...]
vs_general = Dictionary(
title=_("General Properties"),
render='form',
optional_keys=None,
elements=[
single_infos_spec(single_infos),
('name',
TextAscii(
title=_('Unique ID'),
help=_("The ID will be used in URLs that point to a view, e.g. "
"<tt>view.py?view_name=<b>myview</b></tt>. It will also be used "
"internally for identifying a view. You can create several views "
"with the same title but only one per view name. If you create a "
"view that has the same view name as a builtin view, then your "
"view will override that (shadowing it)."),
regex='^[a-zA-Z0-9_]+$',
regex_error=_(
'The name of the view may only contain letters, digits and underscores.'),
size=50,
allow_empty=False)),
('title', TextUnicode(title=_('Title') + '<sup>*</sup>', size=50, allow_empty=False)),
[...]
],
)
[...]
Fix
Checkmk 1.6.0p19 and 2.0.0i1 parses the URL and validates its scheme
against an allowlist before unescaping. JavaScript URLs are therefore
left unescaped and not made clickable:
def escape_text(self, text):
if isinstance(text, HTML):
return "%s" % text # This is HTML code which must not be escaped
text = self.escape_attribute(text)
text = self._unescaper_text.sub(r'<\1\2>', text)
for a_href in self._a_href.finditer(text):
href = a_href.group(1)
parsed = urlparse.urlparse(href)
if parsed.scheme != "" and parsed.scheme not in ["http", "https"]:
continue # Do not unescape links containing disallowed URLs
target = a_href.group(2)
if target:
unescaped_tag = "<a href=\"%s\" target=\"%s\">" % (href, target)
else:
unescaped_tag = "<a href=\"%s\">" % href
text = text.replace(a_href.group(0), unescaped_tag)
return text.replace("&nbsp;", " ")
Timeline
- 2020-10-11: Initial contact with vendor
- 2020-10-12 - 2020-10-14: Further clarification with vendor
- 2020-10-20: Vendor advisory Werk #11501 has been released
- 2020-10-26: Vendor notified me about a patch for Checkmk 1.6.0p19
- 2020-11-17: Applied for CVE
- 2020-11-18: Received CVE-2020-28919
- 2021-12-19: Released blog post
- 2022-01-15: NVD published
17/03/2021
Warning: Rant ahead. Feel free to skip the nstore backend section.
Motivation
I’ve spent the past year looking into the fungi kingdom and the deeper
I look, the weirder it gets. One barrier of entry is identifying
mushrooms, with two different schools of thought:
- Carefully observing their features and using a dichotomous key
system to narrow down to a manageable set of matches. I found
Michael Kuo’s website useful for this.
- Taking a few photos and letting a neural network analyze them.
I’m not a fan of the latter approach for various reasons. You’re at
the mercy of the training set quality, it’s easy to subvert them
and they’re essentially undebuggable. I also found that Wikipedia has
basic identification data on mushrooms. Therefore I thought it to be a
fun exercise to build my own web application for quickly narrowing
down interesting Wikipedia articles to read. You can find the code
over at https://depp.brause.cc/brause.cc/wald/, with the web
application itself hosted on https://wald.brause.cc/.
Data munging
The mushroom data uses so-called mycomorphboxes to hold their
characteristics. Using the Wikipedia API one can query for the latest
revision of every page containing a mycomorphbox template and fetch
its contents in the form of JSON and Wiki markup.
While I like writing scrapers, I dislike that the programs tend to be
messy and require an online connection for every test run. I used the
chance to try out the ETL pattern, that is, writing separate programs
that perform the extraction (downloading data from the service while
avoiding tripping up API limits), transformation (massaging the data
into a form that’s easier to process) and loading (putting the data
into a database). I quite like it. Each part has its own unique
challenges and by sticking to a separate program I can fully focus on
it. Instead of fetching, transforming and loading up the data every
time, I focus on fetching it correctly to disk, then transform the
dump to a more useful form, then figure out how to load it into the
database. If more patterns of that kind emerge, I can see myself
writing utility libraries for them.
Data stores
There were two obvious choices for storing the data:
- Keeping it as JSON and just writing ugly code traversing the parse
tree.
- Using SQLite because it’s a fast and reliable solution. That is,
once you’ve come up with a suitable schema fitting the problem at
hand.
I wanted to try out something different this time, though - something
other than JSON or a relational database. Perhaps something in the
NoSQL realm that’s both pleasant to use and comes with a query
language. Or maybe some dumb key-value store to speed up loading and
dumping the data. I ended up going with a tuple store, but I’m still
considering to give graph and document databases a try. Here’s some
benchmark figures for querying all available filters and filtering
species with a complicated query:
[wasa@box ~]$ time DB=json ./benchmark mushrooms.json >/dev/null
Filters: 14898.5027832031μs
Query stats: 1808.65561523438μs
DB=json ./benchmark mushrooms.json > /dev/null 1.37s user 0.09s system 98% cpu 1.480 total
[wasa@box ~]$ time DB=sqlite ./benchmark db.sqlite3 >/dev/null
Filters: 214.554809570313μs
Query stats: 3953.87497558594μs
DB=sqlite ./benchmark db.sqlite3 > /dev/null 0.24s user 0.01s system 96% cpu 0.253 total
[wasa@box ~]$ time DB=nstore ./benchmark db.lmdb >/dev/null
Filters: 355414.137402344μs
Query stats: 407887.70847168μs
DB=nstore ./benchmark db.lmdb > /dev/null 8.15s user 0.05s system 99% cpu 8.250 total
Bonus: There should be no hardcoded storage solution, but the
possibility to choose it at runtime. This would hopefully not
complicate things too much and encourage cleaner design. For this I
came up with a simple API revolving around establishing/closing a
database connection, performing a transaction on that connection and
querying filters/species on a transaction.
JSON backend
This was rather braindead code. It’s far from pretty, but does the job
surprisingly well. Queries are acceptably fast, so it makes for a nice
fallback. Initial loading time is a bit slow though, using a key-value
store like LMDB would help here. Maybe it’s time for a binary Scheme
serialization solution along the lines of Python’s pickle format, but
without the arbitrary code execution parts…
SQLite backend
It took considerable time to get the schema right. I ended up asking
another SQL expert for help with this and they taught me about EAV
tables. Another oddity was that the database only performed properly
after running ANALYZE once. The code itself is relatively short, but
makes use of lots of string concatenation to generate the search
query.
nstore backend
Retrospectively, this was quite the rabbit hole. I ignored the warning
signs, persisted and eventually got something working. But at what
cost?
My original plan was to use a graph database like Neo4j. I’ve seen it
used for analysis of social graphs, Active Directory networks
and source code. It’s powerful, though clunky and oversized for my
purposes. If I can avoid it, I’d rather not run a separate Java
process and tune its garbage collection settings to play well with
everything else running on my VPS. On top of that I’d need to write a
database adaptor, be it for their HTTP API or the Bolt protocol.
If you’re aware of a comparable in-process solution, I’d be all ears.
It doesn’t even need to do graphs (the data set doesn’t have any
connections), a JSON store with a powerful query language would be
sufficient.
I asked the #scheme channel on Freenode about the topic of graph
databases and was told that tuple stores have equivalent power, while
being considerably easier to implement. SRFI-168 describes a
so-called nstore and comes with a sample in-memory implementation
depending on SRFI-167 and a few others. Getting it running seemed
like an ideal weekend exercise. Or so I thought. I’ve run into the
following obstacles and weeks turned into months of drudgery:
- The specifications themselves are of subpar quality. It seems little
proofreading was done. There are minor errors in the language and
several unclear parts and outright design mistakes that render parts
of the library unusable. Unfortunately I noticed this long after the
SRFI has been finalized. While the process allows for errata, it
took some back and forth to get the most egregious faults in
SRFI-167 fixed. Some faults remain in SRFI-168 and the sample
implementation is incompatible with SRFI-167 due to an API change.
- There is no such thing as a query language. You get basic pattern
matching and SRFI-158 generators. Everything else, like grouping
results or sorting them, you must do yourself. For this reason the
nstore implementation is a bit more verbose than the JSON one.
Relevant webcomic.
- The sample implementation itself depends on several other SRFIs,
most of which I had to port first. Granted, I only did this because
I wanted to contribute them properly to the CHICKEN coop, but it
was still bothersome. I hacked on SRFI-125, SRFI-126, SRFI-145,
SRFI-146, SRFI-158, SRFI-167, SRFI-168 plus alternative versions
of SRFI-125 (using a portable hash tables implementation instead of
the stock one) and SRFI-167 (using LMDB for its backend).
- Some of the SRFIs were particularly difficult to port. SRFI-125
turned out to neither work with stock hash tables (they’re
incompatible with R6RS-style APIs) nor the R6RS-style hash table
implementation provided by SRFI-126 (the stock implementation fails
with custom comparators and the portable SRFI-69 implementation
runs into an infinite loop when executing the test suite). SRFI-167
requires a custom backend for on-disk storage, I initially messed
around with Sophia for this (turned out to be unusable) and
eventually settled for a LMDB-backed implementation. The SRFI-167
and SRFI-168 eggs deviate from the official APIs and have therefore
not been published. For this reason only SRFI-145, SRFI-146 and
SRFI-158 have been added to the coop.
- During the time I worked on the project, some of the links pointing
towards documentation, implementations and example code broke and
pointed nowhere. When I communicated with the author, I got the
impression they had become dissatisfied with the project and wanted
to start over on a clean slate. Links have been replaced, but some
code has been permanently lost. Most recently they admitted they
don’t have any working implementation of SRFI-167 and SRFI-168 at
hand. I consider this a deeply troubling sign for the health of the
project and therefore discourage anyone from relying on it.
- Once I actually got everything running with LMDB for the backing
store, I was surprised to see awful overall performance. Even with
JSON a query takes only a few milliseconds, whereas here it’s two
orders of magnitude more. I did some light profiling and identified
hot paths in both SRFI-128 and SRFI-167. For this reason the web
application is currently using the SQLite backend.
- The APIs themselves are kind of clumsy. I worked around this with my
data storage abstraction, but it’s still something to look out for.
If you compare it to clojure.jdbc or the sql-de-lite egg,
there’s a few obvious usability improvements to be done.
- Eventually, after criticism from other people, the entire SRFI was
considered to be withdrawn. It hasn’t been withdrawn so far as
the process requires a replacement SRFI. I believe this to be a
mistake.
- The SRFI process in general has accelerated in the last few years
due to R7RS-large making heavy use of it for its dockets. There is
the occasional SRFI among them that is too ambitious in scope and
bound to become outdated. I believe this to be an abuse of the
standardization process, instead there should be experimentation on
a decoupled platform such as Snow or Akku. Once the project has
been approved by the community and implemented by several Scheme
systems, it can be considered for standardization. The pre-srfi
repository lists a few upcoming projects of that kind, such as
HTTP servers/clients, a P2P network proposal, a web UI library and
Emacs-style text manipulation. I’m doubtful they will be anywhere as
successful as existing non-portable Scheme libraries.
Needless to say that I’ve become increasingly frustrated over time. To
the SRFI-168 author’s credit, they’ve always been civil, recognized
the design mistakes and are working on a less ambitious replacement
library. While I do regret the time that went into this adventure, I
have learned a few lessons:
- LMDB and key-value stores in general are great. They’re easy to
comprehend, have fast load times and can be a quick and dirty
solution when dealing with relational models is complete overkill.
I’m not sure whether ordered key-value stores are worth it though.
- While it’s true that tuple stores are roughly equivalent in power to
graph databases, graph databases still have the edge. Mind you
though, this piece has been written by a Neo4j person, so it’s most
likely biased. Still, I’m inclined to believe their claims.
- Portable code is cool, but it cannot compete with highly tuned
solutions. Do not expect a sample implementation of a database to
rival SQLite and friends.
Web frontend
I assumed this part to be way harder, but it only took me two days of
hacking without any sort of web framework backing it. I do miss some
of the conveniences I learned from writing Clojure web applications
though:
- I had to write my own database abstraction instead of using
clojure.jdbc and a connection string. On top of that there’s ugly
code to detect which database to use and perform a dynamic import.
- Stuart Sierra’s component library gives you easy dependency
injection. For example you can access configuration and database
connections from a HTTP handler directly instead of having to use
global or dynamically bound variables.
- A ring-style API with a request/response alist and middleware
manipulating them would improve discoverability considerably. It’s
no deal breaker though.
Further thoughts
I’d have expected this project to suck any remaining enthusiasm for
writing web applications out of me, but it didn’t. While I’m not sure
whether I’ll stick to Scheme for them, I could see myself doing
another one soonish. I think I’ll abstain from investing more time
into databases though and hack on something else for the time being.
13/01/2021
My relationship with games is complicated. I never had the chance to
get good at them and few I’ve played have been any good. Despite that,
I had both the urge to complete the game and discover how they work
internally. As nearly all commercially developed games happen to be
proprietary, I focused on viewing and extracting their asset files, an
art not unlike reverse engineering of executable files.
Fast-forward many years and I still occasionally play games. At least
I have proper tools at hand now and the knowledge to make sense of
binary formats. Another plus is that people have come to discover the
benefits of the open source spirit to collaborate and share their
knowledge online. Recently I’ve taken a closer look at a certain meme
game in my Steam library. Many of its assets (music, sound effects,
fonts and a single texture) are stored as regular files on disk,
however, there’s an 79M asset file, presumably holding the missing
textures for the game sprites and backgrounds. This blog post will
explore its custom format and inner workings in enough detail to write
your own extraction program.
Reconnaissance
For starters I’ve opened the file in my favorite hex editor and
browsed through it, looking for obvious patterns such as
human-readable strings, repetitive byte sequences and anything not
looking like random noise. I’ve found the following:
- A very short header that doesn’t contain any human-readable file
signatures.
- Several file paths, each terminated with a null byte.
- Several 16-byte entries, with columns lining up almost perfectly.
- Several concatenated files, identified by file signatures for the
WebP, PNG and XML formats.
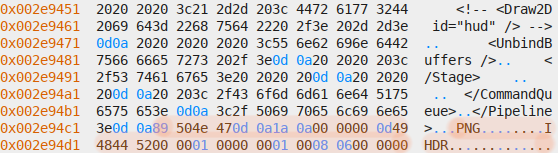
Here’s some screenshots, with the relevant patterns highlighted:
Header and paths section:

Mysterious 16-byte entries, with many even-numbered columns being
zeroes:

WebP file header in files section:

XML file header in files section:
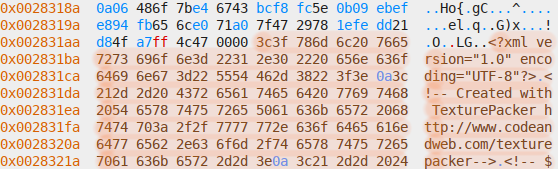
PNG file header in files section:
Given the information so far, several hypotheses can be established:
- The number of paths is the same as the number of embedded files and
every path corresponds to an embedded file.
- The file contains information about how long each embedded file is.
- The mystery section (which I’ll call the index from now on) contains
that information in each of its 16-byte entries
- Each of these entries corresponds to a path and embedded file.
- The association between path, entry and embedded file is ordered,
for example the first path corresponds to the first entry and first
embedded file.
Verification
Each hypothesis can be proven by doing basic mathematics. The most
fundamental assumptions the format relies upon are the number of
paths, index entries and embedded files being the same, and the length
of each embedded file being stored somewhere else in the file,
presumably the index section. I decided to start with the latter, for
which I picked the first embedded file, a WebP image. Its length
can be determined by looking at bytes 4 to 7, decoding them as
unsigned little-endian 32-bit integer and adding 8 to include the
length of the preceding header. The obtained length can be verified by
seeking to the beginning of the file in the hex editor, then seeking
by the length and checking whether that position corresponds to
the start of the next file. Likewise, the length of a PNG file can be
obtained by looking for the IEND sequence followed by a 32-bit
checksum and for XML files by looking for the closing tag.
The first file is 2620176 bytes long and is immediately followed by a
XML file describing it. It corresponds to either 0027fb10 or
10fb2700 when encoded to hex, depending on whether it’s big- or
little-endian. And indeed, the latter value shows up in the last 4
bytes of the first 16-byte entry. I’ve then subsequently verified
whether this property holds true by extracting the file length from
the second 16-byte entry and applying it to the second embedded file.
This left verifying the number of embedded files by counting the
number of paths and entries in their respective sections. I’ve found
335 of them in each, represented as 4f010000 using the previously
encountered little-endian hex notation. That number corresponds to
bytes 4 to 7 in the header, leaving two 4-byte numbers around it. I
haven’t been able to deduce the meaning of the preceding one, but the
succeeding one is a6210000 which corresponds to 8614, the length
of all paths immediately following the file header, thereby giving me
all information necessary to extract the assets.
Further thoughts
Performing the analysis and writing the extraction program took me a
few hours. It could have been a lot trickier, especially if my goal
was to perform game modding. This would require to extract the files,
modify them, then repack them back into the asset file without the
game noticing a change. To do this safely, it’s necessary to perform
deeper analysis of the unknown fields, for example by looking into
other matching metadata of every embedded file or by reverse
engineering the game itself.
Another common problem is that data doesn’t always form clear
patterns, for example if it’s encrypted, compressed or random-looking
for other reasons. Sometimes formats are optimized towards programmer
convenience and may store data necessary to verify the asset file
inside the game instead. This would again not pose a challenge to a
reverse engineer, but would still complicate automatic extraction.
Sometimes team work is necessary. Chances are that tools have been
developed for popular games and may only need minor adjustments to get
working again. One resource I’ve found immensely helpful to gain a
better understanding of common patterns is The Definitive Guide To
Exploring File Formats.
01/11/2020
Update: Added a helpful link explaining more opcodes.
Note: This is an expanded version of this Reddit post.
Advice is one of those Emacs Lisp features that you don’t see often in
other programming languages. It enables you to extend almost any
function you’d like by executing code before/after/instead of it and
messing with arguments/return values. But how does it work? And
which of the two implementations of it should be used?
On advice.el
Somewhat surprisingly, advice.el consists of more than 3000 lines,
but more than half of them are comments. It doesn’t quite reach
literate programming level of commentary, but explains its internals
and includes a small tutorial explaining how it works. There are many
bells and whistles, but to keep things simple I’ll focus on the part
of the tutorial that changes a function to manipulate its argument
before execution of the function body. That body can be
programmatically obtained using symbol-function:
(defun foo (x)
"Add 1 to X."
(1+ x))
(symbol-function 'foo)
;; => (defun foo (x) "Add 1 to X." (1+ x))
The example advice fg-add2 adds one to x again before the
actual code is run:
(defadvice foo (before fg-add2 first)
"Add 2 to X."
(setq x (1+ x)))
(symbol-function 'foo)
;; #[128 "<bytecode>"
;; [apply ad-Advice-foo (lambda (x) "Add 1 to X." (1+ x)) nil]
;; 5 nil]
Yikes. How does one make sense of the byte-code?
Interlude: Byte-code disassembly
Emacs Lisp contains two interpreters, a tree walker (takes a s-exp as
input, walks along it and evaluates the branches) and a byte-code
interpreter (takes bytecode, interprets it using a stack VM).
bytecomp.el and byte-opt.el transform s-expressions into
optimized byte-code. I can recommend studying these to understand how
a simple compiler works. The result of this is code expressed in a
stack-oriented fashion using up to 256 fundamental operations.
One can look at it with the disassemble function, which accepts
both function symbols and function definitions:
(disassemble (lambda () 1))
;; byte code:
;; args: nil
;; 0 constant 1
;; 1 return
What happens here is that the constant 1 is pushed to the stack, then
the top of stack is returned. Arguments are treated in a similar
manner:
(disassemble (lambda (x) x))
;; byte code:
;; args: (x)
;; 0 varref x
;; 1 return
Instead of putting a constant on the stack, the value of x is looked
up and pushed to the stack. Finally, an easy function call looks as
follows:
(disassemble (lambda (a b) (message "%S: %S" a b)))
;; byte code:
;; args: (a b)
;; 0 constant message
;; 1 constant "%S: %S"
;; 2 varref a
;; 3 varref b
;; 4 call 3
;; 5 return
Four values are pushed on the stack in function call order, then a
function is called with three arguments. The four stack values are
replaced with its result, then returned. We’re almost ready to tackle
the actually interesting disassembly now and can look up all other
unknown opcodes in this unofficial manual.
You may wonder though, why bother? Why not just use a decompiler?
Or even avoid dealing with byte-compiled code in the first place…
It turns out there are a few reasons going for it:
- Ideally you’d always have access to source code. This is not always
an option. For example it’s not unheard of for an Emacs
installation to only ship byte-compiled sources (hello Debian).
Likewise defining advice as above will byte-compile the function.
Byte-code compilation is done as performance enhancement and
backtraces from optimized functions will contain byte-code.
- The byte-code decompiler we have is clunky and incomplete. It
sometimes fails to make sense of byte-code, meaning you cannot rely
on it. Another thing to consider is that byte-code doesn’t have to
originate from the official byte-code compiler, there’s other
projects generating byte-code that the decompiler may not target.
Suppose someone wants to thwart analysis of (presumably malicious
code), hand-written byte-code would be an option.
- Sometimes byte-code is studied to understand the performance of an
Emacs Lisp function. It’s easier to reason about byte-code than
regular code, especially to see the effects of lexical binding.
- It’s educational to wade through bytecode.c and other Emacs
internals. While there isn’t too much benefit of understanding
Emacs byte-code, the same lessons apply to other stack-oriented VMs,
such as the JVM. Learning this makes reversing proprietary programs
targeting the JVM (such as Android apps) much easier and enables
advanced techniques such as binary patching.
On advice.el (continued)
We’re ready to unravel what foo does:
(disassemble 'foo)
;; byte code for foo:
;; args: (x)
;; 0 constant apply
;; 1 constant ad-Advice-foo
;; 2 constant (lambda (x) "Add 1 to X." (1+ x))
;; 3 stack-ref 3
;; 4 call 3
;; 5 return
apply, ad-Advice-foo and a lambda are placed on the stack.
Then, stack element 3 (zero-indexed) is added to the top of stack. We
already know that elements 0, 1 and 2 are the three constants, element
3 however is the first argument passed to the function. As it turns
out, when lexical binding is enabled, the stack-ref opcode is used
instead of varref. Therefore the byte-code presented is
equivalent to (lambda (&rest arg) (apply 'ad-Advice-foo (lambda (x)
"Add 1 to X." (1+ x))) arg). You can verify by disassembling that
lambda and compare the output with the previous disassembly.
What does ad-Advice-foo do though?
(disassemble 'ad-Advice-foo)
;; byte code for ad-Advice-foo:
;; args: (ad--addoit-function x)
;; 0 constant nil
;; 1 varbind ad-return-value
;; 2 varref x
;; 3 add1
;; 4 varset x
;; 5 varref ad--addoit-function
;; 6 varref x
;; 7 call 1
;; 8 dup
;; 9 varset ad-return-value
;; 10 unbind 1
;; 11 return
This is a bit more to unravel. varbind introduces a temporary
variable, unbind undoes this binding, varset is equivalent to
set and dup pushes a copy of top of stack (kind of like
stack-ref 0 would do). The sequence of constant nil and
varbind ad-return-value is the same as (let ((ad-return-value
nil)) ...). x is retrieved, incremented by 1 and x set to
the result of that, therefore (setq x (1+ x)). Then
ad--addoit-function is called with x as argument. The result
of that is duplicated and ad-return-value is set to it. Finally
stack item 1 is unbound, presumably the temporary variable. Therefore
the byte-code is equivalent to (let (ad-return-value) (setq x (1+
x)) (setq ad-return-value (funcall ad--addoit-function x))). Let’s
see how nadvice.el fares.
On nadvice.el
It’s tiny compared to advice.el, at only 391 lines of code. To
nobody’s surprise it’s lacking bells and whistles such as changing
argument values directly or not activating advice immediately.
Therefore some adjustments are required to create the equivalent
advice with it:
(defun foo-advice (args)
(mapcar '1+ args))
(advice-add 'foo :filter-args 'foo-advice)
(symbol-function 'foo)
;; #[128 "<bytecode>" [apply foo-advice (lambda (x) "Add 1 to X." (1+ x)) nil] 5 nil]
(disassemble 'foo)
;; byte code for foo:
;; args: (x)
;; 0 constant apply
;; 1 constant (lambda (x) "Add 1 to X." (1+ x))
;; 2 constant foo-advice
;; 3 stack-ref 3
;; 4 call 1
;; 5 call 2
;; 6 return
We have our three constants and x on the stack. At first a
function is called with one argument, that would be foo-advice
with x (which represents the argument list). Then a function is
called with two arguments, that is apply with the lambda and the
result of the previous function call. In other words, (lambda
(&rest x) (apply (lambda (x) "Add 1 to X." (1+ x)) (foo-advice x))).
It was a bit less convenient to write, but far easier to understand.
Conclusion
nadvice.el is surprisingly elegant, striking a good balance
between amount of overall features and technical simplicity. Unless
you maintain a package that must keep compatibility with Emacs 24.3 or
earlier, I don’t see a good reason to go for advice.el.
{kind=link}