Lost In Space
My relationship with games is complicated. I never had the chance to get good at them and few I’ve played have been any good. Despite that, I had both the urge to complete the game and discover how they work internally. As nearly all commercially developed games happen to be proprietary, I focused on viewing and extracting their asset files, an art not unlike reverse engineering of executable files.
Fast-forward many years and I still occasionally play games. At least I have proper tools at hand now and the knowledge to make sense of binary formats. Another plus is that people have come to discover the benefits of the open source spirit to collaborate and share their knowledge online. Recently I’ve taken a closer look at a certain meme game in my Steam library. Many of its assets (music, sound effects, fonts and a single texture) are stored as regular files on disk, however, there’s an 79M asset file, presumably holding the missing textures for the game sprites and backgrounds. This blog post will explore its custom format and inner workings in enough detail to write your own extraction program.
Reconnaissance
For starters I’ve opened the file in my favorite hex editor and browsed through it, looking for obvious patterns such as human-readable strings, repetitive byte sequences and anything not looking like random noise. I’ve found the following:
- A very short header that doesn’t contain any human-readable file signatures.
- Several file paths, each terminated with a null byte.
- Several 16-byte entries, with columns lining up almost perfectly.
- Several concatenated files, identified by file signatures for the WebP, PNG and XML formats.
Here’s some screenshots, with the relevant patterns highlighted:
Header and paths section:

Mysterious 16-byte entries, with many even-numbered columns being zeroes[1]:

WebP file header in files section:

XML file header in files section:
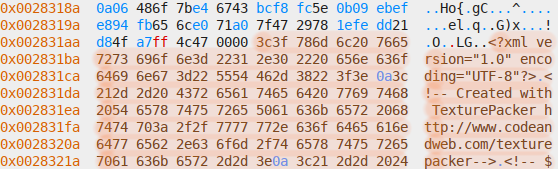
PNG file header in files section:
Given the information so far, several hypotheses can be established:
- The number of paths is the same as the number of embedded files and every path corresponds to an embedded file.
- The file contains information about how long each embedded file is.
- The mystery section (which I’ll call the index from now on) contains that information in each of its 16-byte entries
- Each of these entries corresponds to a path and embedded file.
- The association between path, entry and embedded file is ordered, for example the first path corresponds to the first entry and first embedded file.
Verification
Each hypothesis can be proven by doing basic mathematics. The most fundamental assumptions the format relies upon are the number of paths, index entries and embedded files being the same, and the length of each embedded file being stored somewhere else in the file, presumably the index section. I decided to start with the latter, for which I picked the first embedded file, a WebP image[2]. Its length can be determined by looking at bytes 4 to 7, decoding them as unsigned little-endian 32-bit integer and adding 8 to include the length of the preceding header. The obtained length can be verified by seeking to the beginning of the file in the hex editor, then seeking by the length[3] and checking whether that position corresponds to the start of the next file. Likewise, the length of a PNG file can be obtained by looking for the IEND sequence followed by a 32-bit checksum and for XML files by looking for the closing tag.
The first file is 2620176 bytes long and is immediately followed by a XML file describing it. It corresponds to either 0027fb10 or 10fb2700 when encoded to hex, depending on whether it’s big- or little-endian. And indeed, the latter value shows up in the last 4 bytes of the first 16-byte entry. I’ve then subsequently verified whether this property holds true by extracting the file length from the second 16-byte entry and applying it to the second embedded file.
This left verifying the number of embedded files by counting the number of paths and entries in their respective sections. I’ve found 335 of them in each, represented as 4f010000 using the previously encountered little-endian hex notation. That number corresponds to bytes 4 to 7 in the header, leaving two 4-byte numbers around it. I haven’t been able to deduce the meaning of the preceding one, but the succeeding one is a6210000 which corresponds to 8614, the length of all paths immediately following the file header, thereby giving me all information necessary to extract the assets.
Extraction
The file format deduced so far:
# header # 4-byte integer (unknown) # 4-byte integer (number of filenames) # 4-byte integer (length of filenames section) # paths # null terminated string (path) # repeat count times # index # 4-byte integer (unknown) # 4-byte integer (unknown) # 4-byte integer (unknown) # 4-byte integer (file length) # repeat count times # data # file length bytes # repeat count times
Expressed in pseudo code:
read_integer() filenames_count = read_integer() filenames_length = read_integer() filenames = read_bytes(filenames_length).split("\x00") index = [] for i in range(filenames_count): read_integer() read_integer() read_integer() file_length = read_integer() index[i] = [filenames[i], file_length] for entry in index: data = read_bytes(index[1]) write_bytes(index[0], data)
A reward you’ve earned:
Further thoughts
Performing the analysis and writing the extraction program took me a few hours. It could have been a lot trickier, especially if my goal was to perform game modding. This would require to extract the files, modify them, then repack them back into the asset file without the game noticing a change. To do this safely, it’s necessary to perform deeper analysis of the unknown fields, for example by looking into other matching metadata of every embedded file or by reverse engineering the game itself.
Another common problem is that data doesn’t always form clear patterns, for example if it’s encrypted, compressed or random-looking for other reasons. Sometimes formats are optimized towards programmer convenience and may store data necessary to verify the asset file inside the game instead. This would again not pose a challenge to a reverse engineer, but would still complicate automatic extraction.
Sometimes team work is necessary. Chances are that tools have been developed for popular games and may only need minor adjustments to get working again. One resource I’ve found immensely helpful to gain a better understanding of common patterns is The Definitive Guide To Exploring File Formats.
| [1] | radare2 can shift the file contents around in visual mode by using the h and l movement keys. This is useful to force the entries to align into the expected columns. |
| [2] | The first path suggests a PNG file, but the first embedded file used the WebP format. This threw me off for a while, my working theory is that the artist mislabeled WebP files as PNGs and the game engine they’ve used auto-detected their contents without any hitch. Good for them! |
| [3] | radare2 offers the s+ command for this purpose. |