Been a while since my last CVE :) If you are only interested in how to
protect yourself against this vulnerability, jump to the Mitigation
section. Otherwise, keep on reading.
I’ve attended an application security training by Steven Seeley
last year. One of the recurring themes was lesser known URL handlers
leading to remote code execution (RCE), so we did review a good amount
of Java code implementing JNDI and other fun stuff.
The training left me feeling in need of doing my own security
research. Considering that the last two Emacs releases fixed several
security bugs and I was not aware of any systematic research of URL
handlers in Emacs, I figured that may be something worth sinking my
teeth into.
url.el
This built-in library is the de-facto solution for performing HTTP
requests in Emacs, despite minimal documentation and overall terrible
API. I was vaguely aware that it handles far more than just HTTP URLs,
so I went through the source code and found support for the following:
That’s a lot! Some of the URL handlers were clearly in an unfinished
state as I hit errors when trying to use them. Others outsourced their
functionality to the TRAMP package, which seems like another prime
candidate for future vulnerability research.
Now, given an attacker-controlled URL, what APIs process it? The
obvious answer is url-retrieve and friends, however there is
url-handler-mode as well which enables file system operations
(such as file-exists-p and insert-file-contents) on URLs. This
blog post will focus on the former due to the greater attack surface.
Identifying the sink
With source code review, there is this concept of “source” (code
accepting user input) and “sink” (code performing a dangerous
operation on its argument). The challenge is to find a code path
leading from source to sink. While there is tooling (such as codeql)
to perform automatic analysis, I’m not aware of such a thing for Lisp
languages. The best option so far seem to be source-code aware search
tools, such as semgrep.
I decided to start with the sink first and looked for URL handlers
which unsafely spawn processes using part of the URL as input. This
led to an obvious hit from lisp/url/url-man.el to lisp/man.el:
(defunurl-man(url)"Fetch a Unix manual page URL."(man(url-filenameurl)); [1]nil)
(defunman(man-args)"..."(interactive(list...));; Possibly translate the "subject(section)" syntax into the;; "section subject" syntax and possibly downcase the section.(setqman-args(Man-translate-referencesman-args)); [2](Man-getpage-in-backgroundman-args)); [3]
(defunMan-getpage-in-background(topic)"..."(let*((man-argstopic); [4](bufname(concat"*Man "man-args"*"))(buffer(get-bufferbufname)))(ifbuffer(Man-notify-when-readybuffer)(message"Invoking %s %s in the background"manual-programman-args)(setqbuffer(generate-new-bufferbufname))(with-current-bufferbuffer;; ...(Man-start-calling(if(fboundp'make-process)(let((proc(start-processmanual-programbuffer(if(memqsystem-type'(cygwinwindows-nt))shell-file-name"sh")shell-command-switch(format(Man-build-man-command)man-args)))); [5](set-process-sentinelproc'Man-bgproc-sentinel)(set-process-filterproc'Man-bgproc-filter))(let*((inhibit-read-onlyt)(exit-status(call-processshell-file-namenil(listbuffernil)nilshell-command-switch(format(Man-build-man-command)man-args))); [5](msg""));; ...(Man-bgproc-sentinelbufnamemsg))))))buffer))
To recap:
The file name part of the URL is extracted [1]
man page references are translated, leaving shell control characters
intact [2]
The result is passed to a helper function of man [3][4], which
starts a shell process and interpolates the man page name into the
command line, without any further restriction or escaping of shell
control characters [5]
Despite this seeming relatively straight-forward to exploit, I ran
into a minor impediment almost immediately: The file name part of the
URL does not accept all possible characters unscathed. Inside
url-retrieve, the url-encode-url helper is invoked on a URL
string to ensure it’s normalized and performs percent-encoding on the
path and other parts of the URL. Therefore, the URL handler would need
to percent-decode the path to handle the encoded parts correctly.
Unfortunately, this is not the case for url-man, whereas
url-info does this step.
Given some shell-fu, it is absolutely possible to invoke commands with
several arguments, but this is best left as an exercise to the
inclined reader :)
From sink to source
Here’s the part I spent much more time on: Are there any packages, be
it built-in or from 3rd-party repositories (such as MELPA), which
obtain a URL from user input and retrieve it? How many rely on user
interaction before command execution is triggered?
Initially, I didn’t find much when looking at built-in packages, so I
grabbed a copy of all ELPA repositories from the Emacs China
mirror, unpacked them, searched for url-retrieve invocations and
filtered out anything operating on a string literal. The first
interesting hit was for the org-download package from MELPA, with
500k downloads:
(defunorg-download-yank()"Call `org-download-image' with current kill."(interactive)(let((k(current-kill0))); [1](unless(url-type(url-generic-parse-urlk))(user-error"Not a URL: %s"k))(org-download-image; [2](replace-regexp-in-string"\n+$"""k))))(defunorg-download-image(link)"Save image at address LINK to `org-download--dir'."(interactive"sUrl: ")(let*((link-and-ext(org-download--parse-linklink)); [3];; ...);; ...))(defunorg-download--parse-link(link)(cond((image-type-from-file-namelink)(listlinknil))((string-match"^file:/+"link)(listlinknil))(t(let((buffer(url-retrieve-synchronouslylinkt))); [4](org-download--detect-extlinkbuffer)))))
The exploit scenario would look as follows:
The user downloads an Org file containing a malicious man: link
She yanks the link, then processes it with the org-download-yank
command
The embedded shell command inside the link is executed
Granted, not a very likely scenario, but good enough for an initial
security report to the Emacs maintainers[6]. This revealed that the
sink had been patched almost a year ago in commit 820f0793f0b, which
did not make it into a stable release yet and was intended to land in
Emacs 30.1. From my own limited testing, I managed to reproduce the
bug on Emacs versions 29.4 (Arch), 28.2/27.1/26.1 (Debian 12/11/10)
and 25.2/24.5 (Ubuntu 18.04/16.04).
The initial response to the report was mixed. On the one hand it
seemed like a serious enough issue to the maintainers to further look
into, on the other hand the initial response in the Debbugs thread was
“Why isn’t it a problem with the command that invokes ‘man’, in this
case Org?” and “I think callers of ‘man’ should prevent that instead.”
I do find it perfectly understandable that the focus of the Emacs
maintainers is fixing code that’s part of Emacs, the initial response
not so much. Nevertheless, I felt that I had to prove it’s not only
third-party packages that can trigger the bug, which motivated me to
look harder for a more realistic exploit scenario.
Reducing user interaction
I reviewed the Emacs 29.4 sources again. This led me towards eww.el
and shr.el which are responsible for the textual browser and HTML
rendering respectively. For example, the following browser command
downloads the URL at point:
(defuneww-download()"Download URL to `eww-download-directory'.
Use link at point if there is one, else the current page's URL."(interactivenileww-mode)(let((dir(if(stringpeww-download-directory)eww-download-directory(funcalleww-download-directory))))(access-filedir"Download failed")(let((url(or(get-text-property(point)'shr-url); [1](eww-current-url))))(if(noturl)(message"No URL under point")(url-retrieveurl#'eww-download-callback(listurldir)))))); [2]
This improves upon the initial payload by not requiring any 3rd-party
packages, but still relies on the position of point and intentionally
executing the command.
I started experimenting with other HTML tags containing URLs and
noticed that there was nothing preventing an image from containing a
man: URL. To my surprise, merely rendering an HTML document with
shr.el triggered URL retrieval:
(defunshr-tag-img(dom&optionalurl)(when(orurl(anddom(or(>(length(dom-attrdom'src))0)(>(length(dom-attrdom'srcset))0))))(when(>(current-column)0)(insert"\n"))(let((alt(dom-attrdom'alt))(width(shr-string-number(dom-attrdom'width)))(height(shr-string-number(dom-attrdom'height)))(url(shr-expand-url(orurl(shr--preferred-imagedom))))); [1](let((start(point-marker)))(when(zerop(lengthalt))(setqalt"*"))(cond((nullurl);; After further expansion, there turned out to be no valid;; src in the img after all.)((or(member(dom-attrdom'height)'("0""1"))(member(dom-attrdom'width)'("0""1")));; Ignore zero-sized or single-pixel images.);; ...(t;; ...(url-queue-retrieveurl#'shr-image-fetched; [2](list(current-buffer)start(set-marker(make-marker)(point))(list:widthwidth:heightheight))t(not(shr--use-cookies-purlshr-base)))));; ...))))
This reduces user interaction to rendering a HTML document, regardless
of whether it’s with a textual browser, newsreader, EPUB viewer, etc.
Even something as simple as customizing
browse-url-browser-function to eww-browse-url would make
clicking links dangerous. At this point, maintainers agreed that it
would make sense to apply for a CVE. I recorded a video of the Proof
of Concept (PoC) in action to demonstrate the bug:
Besides the browser, email clients are of particular concern as
they’re designed to handle messages originating from the internet.
I’ve compiled the following table summarizing impact for commonly used
clients. Two attack scenarios are of interest here, the previously
shown inline images and clicking external links, which is explained in
the following sections.
When xristos saw the above PoC video, he initially thought it abused
a HTTP redirect to a malicious URL. This turned out to be another
viable approach due to url-http.el automatically following redirects.
However, this makes exploitation a bit more involved:
The attacker needs to host a malicious HTTP server
That server needs to respond to a particular HTTP request with a
redirect to a malicious URL
The attacker needs to share the URL leading to the redirect
The victim needs to url-retrieve that URL with a vulnerable
Emacs version
A realistic scenario would be a URL previewer. For example, the Circe
IRC client includes the circe-display-images module which fetches
every incoming image URL matching a regular expression. All an
attacker would need to do is to join an IRC channel and send messages
containing a link to the malicious HTTP server:
(enable-circe-display-images);; post something http://example.com/evil.{png,jpg,svg,gif}
A much more evil scenario I can think of:
Someone™ operates a reasonably popular website visited by Emacs
users
They check their web server logs for user agents and discover url.el
among them
They set up the web server to conditionally serve the malicious
redirect for a URL mainly visited by url.el (for example, an Atom
feed)
The built-in Newsticker package defaults to fetching feeds with url.el
since at least 2008.
Towards the end of this research, I started experimenting with
semgrep to reduce the amount of code to sift through. Its Lisp
support is still marked as experimental[10], but I still managed to
write useful rules that flag dodgy sinks and sources. For example, the
following rule set matches all url-retrieve calls not using a
string literal:
Unfortunately, this is insufficient due to the highly dynamic nature
of Emacs Lisp. For example, it’s possible to stuff a symbol name into
a variable and later call it with funcall/apply/eval and
alike. To cover this as well, I’ve created an additional rule
searching for such suspiciously named symbols, but due to the
capability of creating such symbols on the fly, this remains
insufficient. Nevertheless, I do appreciate assistance to avoid code
review fatigue. If it’s possible to write a rule for a specific bug
and use it to eliminate all variants, that’s as good as it gets.
Mitigation
The most important mitigation has already been applied. If you can,
update to Emacs 30.1. For example, Ubuntu allows installing Emacs via
Snap, which gives you the latest stable version. Alternatively, make
sure to install security updates. For example, Debian Stable backports
relevant patches to older package versions. Finally, you can manually
apply the patch to older Emacs versions by wrapping the new definition
of Man-translate-references in a (with-eval-after-load 'man
...) form:
Assuming neither of the previous options are to your liking, you can
work around the issue by adding the following snippet to your init
file:
(defunmy-man-interactive-check(_)(when(not(called-interactively-p'interactive))(error"Called from URL handler, aborting...")))(with-eval-after-load'man(advice-add'man:before#'my-man-interactive-check))
To systematically fix this issue and prevent it from reoccurring, we
need to take a step back and re-architect some fundamental assumptions
about how URLs should be retrieved:
Inside a browser, there is a limited amount of URL handlers that can
be processed meaningfully. In practice that would be http:// /
https:// / file://, maybe ftp://. However, there is no
API to specify what URL handlers should be used. Instead, merely
specifying a URL with a not yet encountered handler is sufficient to
lazily load up the respective URL handler backend. Worse, a user
cannot even customize the list of disallowed URL handlers, which
makes workarounds needlessly difficult.
When handling HTTP redirects, cross-protocol redirects are allowed.
This is sort of unexpected. It makes a lot of sense to redirect from
http:// to https://, but not so much to man:. Android
systems for example pop up a prompt if an unexpected URL handler is
triggered. This additional friction may help things a bit.
Given how nearly all use of url.el restricts itself to HTTP, people
desiring a safer library may be happier with an alternative only
supporting HTTP. plz.el may get there, eventually.
A more narrow fix would be to eliminate all unsafe process invocations
and substitute them with less error-prone APIs that are safe by
design. While I do believe this to be a worthwhile goal, this would
leave the door open for other ways of URL handler abuse.
Future research
There is still other URL handling code to look at:
URL handlers utilizing TRAMP (for example, eww.el contains code
to ensure file: URLs to remote resources are retrieved…)
url-handler-mode and all file-related APIs that accept URLs with
it enabled
Remaining code in url-handlers.el (url-copy-file,
url-insert-file-contents, etc.)
browse-url.el and ffap.el
Org’s org-protocol:// and TRAMP’s path handler
To help other security researchers with discovery of new
vulnerabilities, improving semgrep and sharing rules would be very
useful.
Timeline
2024-11-02: Contacted Emacs maintainers with an initial PoC in a 3rd-party package
2024-11-03: Discovered the vulnerability is fixed on the master branch
2024-11-04: Submitted an improved PoC using a built-in package, but requires user interaction
2024-11-05: Submitted an improved PoC that reduces user interaction to opening a website in the eww browser
2024-11-20: Created a video of the above PoC
2024-11-21: xristos discovered an alternative PoC with zero user interaction
2024-11-25: Recreated above PoC, started writing a blog post
Analysis of the Emacs sources raised many errors in the lexing
code. Sometimes only a few lines were skipped, occasionally an
entire file was invisible to the rule matching engine. Perhaps
using tree-sitter for parsing would help?
Note: The \037 sequence appearing in the code snippets is one
character, escaped for readability.
It’s been eight years since I started using Emacs and Emacs Lisp and I
still keep running into dusty corners. Traditionally, Lisp dialects
use the semicolon for line comments, with block and s-expression
comments being optional features.
The #@COUNT construct, which skips the next COUNT characters,
is useful for program-generated comments containing binary data.
The Emacs Lisp byte compiler uses this in its output files (see
“Byte Compilation”). It isn’t meant for source files, however.
At first sight, this seems useless. This feature is meant to be used
in .elc, not .el files and looking at a file produced by the
byte compiler, its only use is to emit docstrings:
;;; This file uses dynamic docstrings, first added in Emacs 19.29.[...]#@11docstring\037(defalias'my-test#[...])
This is kind of like a block-comment, except there is no comment
terminator. For this reason, the characters to be commented out need
to be counted. You’d think that the following would work, but it
fails with an “End of file during parsing” error:
#define FROM_FILE_P(readcharfun) \
(EQ (readcharfun, Qget_file_char) \
|| EQ (readcharfun, Qget_emacs_mule_file_char))
staticvoidskip_dyn_bytes(Lisp_Objectreadcharfun,ptrdiff_tn){if(FROM_FILE_P(readcharfun)){block_input();/* FIXME: Not sure if it's needed. */fseek(infile->stream,n-infile->lookahead,SEEK_CUR);unblock_input();infile->lookahead=0;}else{/* We're not reading directly from a file. In that case, it's difficult
to reliably count bytes, since these are usually meant for the file's
encoding, whereas we're now typically in the internal encoding.
But luckily, skip_dyn_bytes is used to skip over a single
dynamic-docstring (or dynamic byte-code) which is always quoted such
that \037 is the final char. */intc;do{c=READCHAR;}while(c>=0&&c!='\037');}}
Due to encoding difficulties, the #@COUNT construct is always used
with a terminating \037 AKA unit separator character. While it
seems that the FROM_FILE_P macro applies when using the reader
with get-file-char or get-emacs-mule-file-char (which are used
by load internally), I never managed to trigger that code path.
The reader therefore seems to always ignore the count argument,
essentially turning #@COUNT into a block comment facility.
Given this information, one could obfuscate Emacs Lisp code to hide
something unusual going on:
(message"Fire the %s!!!"#@11"rockets")\037(reverse"sekun"))
In case you want to experiment with this and want to use the correct
counts, here’s a quick and dirty command:
(defuncursed-elisp-block-comment(begend)(interactive"r")(save-excursion(save-restriction(narrow-to-regionbegend)(goto-char(point-min));; account for space and terminator(insert(format"#@%d "(+(-endbeg)2)))(goto-char(point-max))(insert"\037"))))
/* Read a decimal integer. */while((c=READCHAR)>=0&&c>='0'&&c<='9'){if((STRING_BYTES_BOUND-extra)/10<=nskip)string_overflow();digits++;nskip*=10;nskip+=c-'0';if(digits==2&&nskip==0){/* We've just seen #@00, which means "skip to end". */skip_dyn_eof(readcharfun);returnQnil;}}
The EOF comment version can be used to create polyglots. An Emacs Lisp
script could end with #@00, then concatenated with a file
tolerating leading garbage. The ZIP format is known for its permissive
behavior, thereby allowing you to embed several resources into one
file:
[wasa@box ~]$ catpolyglot.el(message "This could be a whole wordle game")(message "I've attached some dictionaries for you though")#@00[wasa@box ~]$ catpolyglot.elwordle.zip>wordle.el[wasa@box ~]$ filewordle.elwordle.el: data
[wasa@box ~]$ emacs--scriptwordle.elThis could be a whole wordle game
I've attached some dictionaries for you though
[wasa@box ~]$ unzipwordle.elArchive: wordle.el
warning [wordle.el]: 109 extra bytes at beginning or within zipfile
(attempting to process anyway)
inflating: wordle.de
inflating: wordle.uk
This could be combined with the multi-line shebang trick to create a
self-extracting archive format. Or maybe an installer? Or just a
script that can access its own resources? Let me know if you have any
interesting ideas.
Strictly speaking, #+(or) isn’t a comment, but a
conditional reader construct with an always false feature test.
While one may shorten it to #+nil or #-t, that would be
incorrect because both may be registered features.
I’ve discovered a trivial stored XSS vulnerability in Checkmk 1.6.0p18
during an on-site penetration test and disclosed it responsibly to the
tribe29 GmbH. The vendor promptly confirmed the issue, fixed it and
announced an advisory. I’ve applied for a CVE, but didn’t get around
explaining the vulnerability in detail, therefore I’m publishing this
blog post to complete the process.
The vulnerability requires an authenticated attacker with permission
to configure and share a custom view. Given these prerequisites, they
can inject arbitrary JavaScript into the view title by inserting a
HTML link with a JavaScript URL. If the attacker manages to trick a
user into clicking that link, the JavaScript URL is executed within
the user’s browser context.
There is a CSP policy in place, but it does not mitigate inline
JavaScript code in event handlers, links or script tags. An attacker
could therefore obtain confidential user data or perform UI
redressing.
The vulnerable code has been identified in versions below 1.6.0p18,
such as 1.6.0 and older. It is unclear in which version the
vulnerability has been introduced, therefore it’s recommended to
update to 1.6.0p19/2.0.0i1 or newer.
Detailed description
The Checkmk GUI code uses a WordPress-style approach to handle HTML:
User input is encoded using HTML entities, then selectively decoded
with a regular expression looking for simple tags. As a special case,
the <a> tag gets its href attribute unescaped as well to
enable hyperlinks. The attribute is not checked for its protocol,
thereby allowing URLs such as javascript:alert(1).
classEscaper(object):def__init__(self):super(Escaper,self).__init__()self._unescaper_text=re.compile(r'<(/?)(h1|h2|b|tt|i|u|br(?: /)?|nobr(?: /)?|pre|a|sup|p|li|ul|ol)>')self._quote=re.compile(r"(?:"|')")self._a_href=re.compile(r'<a href=((?:"|').*?(?:"|'))>')[...]defescape_text(self,text):ifisinstance(text,HTML):return"%s"%text# This is HTML code which must not be escapedtext=self.escape_attribute(text)text=self._unescaper_text.sub(r'<\1\2>',text)fora_hrefinself._a_href.finditer(text):text=text.replace(a_href.group(0),"<a href=%s>"%self._quote.sub("\"",a_href.group(1)))returntext.replace("&nbsp;"," ")
The above code is used for HTML generation. To exploit it, I started
looking for a HTML form and found that when editing a custom view, no
user input validation is performed on the view title (as opposed to
the view name).
defpage_edit_visual(what,all_visuals,custom_field_handler=None,create_handler=None,load_handler=None,info_handler=None,sub_pages=None):[...]html.header(title)html.begin_context_buttons()back_url=html.get_url_input("back","edit_%s.py"%what)html.context_button(_("Back"),back_url,"back")[...]vs_general=Dictionary(title=_("General Properties"),render='form',optional_keys=None,elements=[single_infos_spec(single_infos),('name',TextAscii(title=_('Unique ID'),help=_("The ID will be used in URLs that point to a view, e.g. ""<tt>view.py?view_name=<b>myview</b></tt>. It will also be used ""internally for identifying a view. You can create several views ""with the same title but only one per view name. If you create a ""view that has the same view name as a builtin view, then your ""view will override that (shadowing it)."),regex='^[a-zA-Z0-9_]+$',regex_error=_('The name of the view may only contain letters, digits and underscores.'),size=50,allow_empty=False)),('title',TextUnicode(title=_('Title')+'<sup>*</sup>',size=50,allow_empty=False)),[...]],)[...]
Fix
Checkmk 1.6.0p19 and 2.0.0i1 parses the URL and validates its scheme
against an allowlist before unescaping. JavaScript URLs are therefore
left unescaped and not made clickable:
defescape_text(self,text):ifisinstance(text,HTML):return"%s"%text# This is HTML code which must not be escapedtext=self.escape_attribute(text)text=self._unescaper_text.sub(r'<\1\2>',text)fora_hrefinself._a_href.finditer(text):href=a_href.group(1)parsed=urlparse.urlparse(href)ifparsed.scheme!=""andparsed.schemenotin["http","https"]:continue# Do not unescape links containing disallowed URLstarget=a_href.group(2)iftarget:unescaped_tag="<a href=\"%s\" target=\"%s\">"%(href,target)else:unescaped_tag="<a href=\"%s\">"%hreftext=text.replace(a_href.group(0),unescaped_tag)returntext.replace("&nbsp;"," ")
Timeline
2020-10-11: Initial contact with vendor
2020-10-12 - 2020-10-14: Further clarification with vendor
2020-10-20: Vendor advisory Werk #11501 has been released
2020-10-26: Vendor notified me about a patch for Checkmk 1.6.0p19
Warning: Rant ahead. Feel free to skip the nstore backend section.
Motivation
I’ve spent the past year looking into the fungi kingdom and the deeper
I look, the weirder it gets. One barrier of entry is identifying
mushrooms, with two different schools of thought:
Carefully observing their features and using a dichotomous key
system to narrow down to a manageable set of matches. I found
Michael Kuo’s website useful for this.
Taking a few photos and letting a neural network analyze them.
I’m not a fan of the latter approach for various reasons. You’re at
the mercy of the training set quality, it’s easy to subvert them
and they’re essentially undebuggable. I also found that Wikipedia has
basic identification data on mushrooms. Therefore I thought it to be a
fun exercise to build my own web application for quickly narrowing
down interesting Wikipedia articles to read. You can find the code
over at https://depp.brause.cc/brause.cc/wald/, with the web
application itself hosted on https://wald.brause.cc/.
Data munging
The mushroom data uses so-called mycomorphboxes to hold their
characteristics. Using the Wikipedia API one can query for the latest
revision of every page containing a mycomorphbox template and fetch
its contents in the form of JSON and Wiki markup.
While I like writing scrapers, I dislike that the programs tend to be
messy and require an online connection for every test run. I used the
chance to try out the ETL pattern, that is, writing separate programs
that perform the extraction (downloading data from the service while
avoiding tripping up API limits), transformation (massaging the data
into a form that’s easier to process) and loading (putting the data
into a database). I quite like it. Each part has its own unique
challenges and by sticking to a separate program I can fully focus on
it. Instead of fetching, transforming and loading up the data every
time, I focus on fetching it correctly to disk, then transform the
dump to a more useful form, then figure out how to load it into the
database. If more patterns of that kind emerge, I can see myself
writing utility libraries for them.
Data stores
There were two obvious choices for storing the data:
Keeping it as JSON and just writing ugly code traversing the parse
tree.
Using SQLite because it’s a fast and reliable solution. That is,
once you’ve come up with a suitable schema fitting the problem at
hand.
I wanted to try out something different this time, though - something
other than JSON or a relational database. Perhaps something in the
NoSQL realm that’s both pleasant to use and comes with a query
language. Or maybe some dumb key-value store to speed up loading and
dumping the data. I ended up going with a tuple store, but I’m still
considering to give graph and document databases a try. Here’s some
benchmark figures for querying all available filters and filtering
species with a complicated query:
[wasa@box ~]$ timeDB=json./benchmarkmushrooms.json>/dev/nullFilters: 14898.5027832031μs
Query stats: 1808.65561523438μs
DB=json ./benchmark mushrooms.json > /dev/null 1.37s user 0.09s system 98% cpu 1.480 total
[wasa@box ~]$ timeDB=sqlite./benchmarkdb.sqlite3>/dev/nullFilters: 214.554809570313μs
Query stats: 3953.87497558594μs
DB=sqlite ./benchmark db.sqlite3 > /dev/null 0.24s user 0.01s system 96% cpu 0.253 total
[wasa@box ~]$ timeDB=nstore./benchmarkdb.lmdb>/dev/nullFilters: 355414.137402344μs
Query stats: 407887.70847168μs
DB=nstore ./benchmark db.lmdb > /dev/null 8.15s user 0.05s system 99% cpu 8.250 total
Bonus: There should be no hardcoded storage solution, but the
possibility to choose it at runtime. This would hopefully not
complicate things too much and encourage cleaner design. For this I
came up with a simple API revolving around establishing/closing a
database connection, performing a transaction on that connection and
querying filters/species on a transaction.
JSON backend
This was rather braindead code. It’s far from pretty, but does the job
surprisingly well. Queries are acceptably fast, so it makes for a nice
fallback. Initial loading time is a bit slow though, using a key-value
store like LMDB would help here. Maybe it’s time for a binary Scheme
serialization solution along the lines of Python’s pickle format, but
without the arbitrary code execution parts…
SQLite backend
It took considerable time to get the schema right. I ended up asking
another SQL expert for help with this and they taught me about EAV
tables. Another oddity was that the database only performed properly
after running ANALYZE once. The code itself is relatively short, but
makes use of lots of string concatenation to generate the search
query.
nstore backend
Retrospectively, this was quite the rabbit hole. I ignored the warning
signs, persisted and eventually got something working. But at what
cost?
My original plan was to use a graph database like Neo4j. I’ve seen it
used for analysis of social graphs, Active Directory networks
and source code. It’s powerful, though clunky and oversized for my
purposes. If I can avoid it, I’d rather not run a separate Java
process and tune its garbage collection settings to play well with
everything else running on my VPS. On top of that I’d need to write a
database adaptor, be it for their HTTP API or the Bolt protocol.
If you’re aware of a comparable in-process solution, I’d be all ears.
It doesn’t even need to do graphs (the data set doesn’t have any
connections), a JSON store with a powerful query language would be
sufficient.
I asked the #scheme channel on Freenode about the topic of graph
databases and was told that tuple stores have equivalent power, while
being considerably easier to implement. SRFI-168 describes a
so-called nstore and comes with a sample in-memory implementation
depending on SRFI-167 and a few others. Getting it running seemed
like an ideal weekend exercise. Or so I thought. I’ve run into the
following obstacles and weeks turned into months of drudgery:
The specifications themselves are of subpar quality. It seems little
proofreading was done. There are minor errors in the language and
several unclear parts and outright design mistakes that render parts
of the library unusable. Unfortunately I noticed this long after the
SRFI has been finalized. While the process allows for errata, it
took some back and forth to get the most egregious faults in
SRFI-167 fixed. Some faults remain in SRFI-168 and the sample
implementation is incompatible with SRFI-167 due to an API change.
There is no such thing as a query language. You get basic pattern
matching and SRFI-158 generators. Everything else, like grouping
results or sorting them, you must do yourself. For this reason the
nstore implementation is a bit more verbose than the JSON one.
Relevant webcomic.
The sample implementation itself depends on several other SRFIs,
most of which I had to port first. Granted, I only did this because
I wanted to contribute them properly to the CHICKEN coop, but it
was still bothersome. I hacked on SRFI-125, SRFI-126, SRFI-145,
SRFI-146, SRFI-158, SRFI-167, SRFI-168 plus alternative versions
of SRFI-125 (using a portable hash tables implementation instead of
the stock one) and SRFI-167 (using LMDB for its backend).
Some of the SRFIs were particularly difficult to port. SRFI-125
turned out to neither work with stock hash tables (they’re
incompatible with R6RS-style APIs) nor the R6RS-style hash table
implementation provided by SRFI-126 (the stock implementation fails
with custom comparators and the portable SRFI-69 implementation
runs into an infinite loop when executing the test suite). SRFI-167
requires a custom backend for on-disk storage, I initially messed
around with Sophia for this (turned out to be unusable) and
eventually settled for a LMDB-backed implementation. The SRFI-167
and SRFI-168 eggs deviate from the official APIs and have therefore
not been published. For this reason only SRFI-145, SRFI-146 and
SRFI-158 have been added to the coop.
During the time I worked on the project, some of the links pointing
towards documentation, implementations and example code broke and
pointed nowhere. When I communicated with the author, I got the
impression they had become dissatisfied with the project and wanted
to start over on a clean slate. Links have been replaced, but some
code has been permanently lost. Most recently they admitted they
don’t have any working implementation of SRFI-167 and SRFI-168 at
hand. I consider this a deeply troubling sign for the health of the
project and therefore discourage anyone from relying on it.
Once I actually got everything running with LMDB for the backing
store, I was surprised to see awful overall performance. Even with
JSON a query takes only a few milliseconds, whereas here it’s two
orders of magnitude more. I did some light profiling and identified
hot paths in both SRFI-128 and SRFI-167. For this reason the web
application is currently using the SQLite backend.
The APIs themselves are kind of clumsy. I worked around this with my
data storage abstraction, but it’s still something to look out for.
If you compare it to clojure.jdbc or the sql-de-lite egg,
there’s a few obvious usability improvements to be done.
The SRFI process in general has accelerated in the last few years
due to R7RS-large making heavy use of it for its dockets. There is
the occasional SRFI among them that is too ambitious in scope and
bound to become outdated. I believe this to be an abuse of the
standardization process, instead there should be experimentation on
a decoupled platform such as Snow or Akku. Once the project has
been approved by the community and implemented by several Scheme
systems, it can be considered for standardization. The pre-srfi
repository lists a few upcoming projects of that kind, such as
HTTP servers/clients, a P2P network proposal, a web UI library and
Emacs-style text manipulation. I’m doubtful they will be anywhere as
successful as existing non-portable Scheme libraries.
Needless to say that I’ve become increasingly frustrated over time. To
the SRFI-168 author’s credit, they’ve always been civil, recognized
the design mistakes and are working on a less ambitious replacement
library. While I do regret the time that went into this adventure, I
have learned a few lessons:
LMDB and key-value stores in general are great. They’re easy to
comprehend, have fast load times and can be a quick and dirty
solution when dealing with relational models is complete overkill.
I’m not sure whether ordered key-value stores are worth it though.
While it’s true that tuple stores are roughly equivalent in power to
graph databases, graph databases still have the edge. Mind you
though, this piece has been written by a Neo4j person, so it’s most
likely biased. Still, I’m inclined to believe their claims.
Portable code is cool, but it cannot compete with highly tuned
solutions. Do not expect a sample implementation of a database to
rival SQLite and friends.
Web frontend
I assumed this part to be way harder, but it only took me two days of
hacking without any sort of web framework backing it. I do miss some
of the conveniences I learned from writing Clojure web applications
though:
I had to write my own database abstraction instead of using
clojure.jdbc and a connection string. On top of that there’s ugly
code to detect which database to use and perform a dynamic import.
Stuart Sierra’s component library gives you easy dependency
injection. For example you can access configuration and database
connections from a HTTP handler directly instead of having to use
global or dynamically bound variables.
A ring-style API with a request/response alist and middleware
manipulating them would improve discoverability considerably. It’s
no deal breaker though.
Further thoughts
I’d have expected this project to suck any remaining enthusiasm for
writing web applications out of me, but it didn’t. While I’m not sure
whether I’ll stick to Scheme for them, I could see myself doing
another one soonish. I think I’ll abstain from investing more time
into databases though and hack on something else for the time being.
My relationship with games is complicated. I never had the chance to
get good at them and few I’ve played have been any good. Despite that,
I had both the urge to complete the game and discover how they work
internally. As nearly all commercially developed games happen to be
proprietary, I focused on viewing and extracting their asset files, an
art not unlike reverse engineering of executable files.
Fast-forward many years and I still occasionally play games. At least
I have proper tools at hand now and the knowledge to make sense of
binary formats. Another plus is that people have come to discover the
benefits of the open source spirit to collaborate and share their
knowledge online. Recently I’ve taken a closer look at a certain meme
game in my Steam library. Many of its assets (music, sound effects,
fonts and a single texture) are stored as regular files on disk,
however, there’s an 79M asset file, presumably holding the missing
textures for the game sprites and backgrounds. This blog post will
explore its custom format and inner workings in enough detail to write
your own extraction program.
Reconnaissance
For starters I’ve opened the file in my favorite hex editor and
browsed through it, looking for obvious patterns such as
human-readable strings, repetitive byte sequences and anything not
looking like random noise. I’ve found the following:
A very short header that doesn’t contain any human-readable file
signatures.
Several file paths, each terminated with a null byte.
Several 16-byte entries, with columns lining up almost perfectly.
Several concatenated files, identified by file signatures for the
WebP, PNG and XML formats.
Here’s some screenshots, with the relevant patterns highlighted:
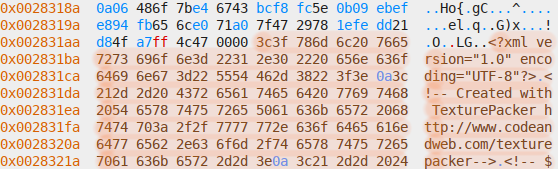
Header and paths section:
Mysterious 16-byte entries, with many even-numbered columns being
zeroes[1]:
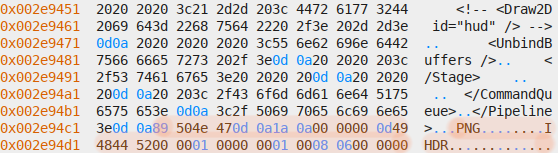
WebP file header in files section:
XML file header in files section:
PNG file header in files section:
Given the information so far, several hypotheses can be established:
The number of paths is the same as the number of embedded files and
every path corresponds to an embedded file.
The file contains information about how long each embedded file is.
The mystery section (which I’ll call the index from now on) contains
that information in each of its 16-byte entries
Each of these entries corresponds to a path and embedded file.
The association between path, entry and embedded file is ordered,
for example the first path corresponds to the first entry and first
embedded file.
Verification
Each hypothesis can be proven by doing basic mathematics. The most
fundamental assumptions the format relies upon are the number of
paths, index entries and embedded files being the same, and the length
of each embedded file being stored somewhere else in the file,
presumably the index section. I decided to start with the latter, for
which I picked the first embedded file, a WebP image[2]. Its length
can be determined by looking at bytes 4 to 7, decoding them as
unsigned little-endian 32-bit integer and adding 8 to include the
length of the preceding header. The obtained length can be verified by
seeking to the beginning of the file in the hex editor, then seeking
by the length[3] and checking whether that position corresponds to
the start of the next file. Likewise, the length of a PNG file can be
obtained by looking for the IEND sequence followed by a 32-bit
checksum and for XML files by looking for the closing tag.
The first file is 2620176 bytes long and is immediately followed by a
XML file describing it. It corresponds to either 0027fb10 or
10fb2700 when encoded to hex, depending on whether it’s big- or
little-endian. And indeed, the latter value shows up in the last 4
bytes of the first 16-byte entry. I’ve then subsequently verified
whether this property holds true by extracting the file length from
the second 16-byte entry and applying it to the second embedded file.
This left verifying the number of embedded files by counting the
number of paths and entries in their respective sections. I’ve found
335 of them in each, represented as 4f010000 using the previously
encountered little-endian hex notation. That number corresponds to
bytes 4 to 7 in the header, leaving two 4-byte numbers around it. I
haven’t been able to deduce the meaning of the preceding one, but the
succeeding one is a6210000 which corresponds to 8614, the length
of all paths immediately following the file header, thereby giving me
all information necessary to extract the assets.
Extraction
The file format deduced so far:
# header
# 4-byte integer (unknown)
# 4-byte integer (number of filenames)
# 4-byte integer (length of filenames section)
# paths
# null terminated string (path)
# repeat count times
# index
# 4-byte integer (unknown)
# 4-byte integer (unknown)
# 4-byte integer (unknown)
# 4-byte integer (file length)
# repeat count times
# data
# file length bytes
# repeat count times
Performing the analysis and writing the extraction program took me a
few hours. It could have been a lot trickier, especially if my goal
was to perform game modding. This would require to extract the files,
modify them, then repack them back into the asset file without the
game noticing a change. To do this safely, it’s necessary to perform
deeper analysis of the unknown fields, for example by looking into
other matching metadata of every embedded file or by reverse
engineering the game itself.
Another common problem is that data doesn’t always form clear
patterns, for example if it’s encrypted, compressed or random-looking
for other reasons. Sometimes formats are optimized towards programmer
convenience and may store data necessary to verify the asset file
inside the game instead. This would again not pose a challenge to a
reverse engineer, but would still complicate automatic extraction.
Sometimes team work is necessary. Chances are that tools have been
developed for popular games and may only need minor adjustments to get
working again. One resource I’ve found immensely helpful to gain a
better understanding of common patterns is The Definitive Guide To
Exploring File Formats.
radare2 can shift the file contents around in visual mode
by using the h and l movement keys. This is useful to
force the entries to align into the expected columns.
The first path suggests a PNG file, but the first embedded file
used the WebP format. This threw me off for a while, my working
theory is that the artist mislabeled WebP files as PNGs and the
game engine they’ve used auto-detected their contents without
any hitch. Good for them!



{kind=link}